Distributed Machine Learning
Summary
A Survey on Distributed Machine Learning (2019)
ML Infra
Benefits of a distributed ML system:
- an increase of parallelization and the total amount of I/O bandwidth
- being able to handle inherently distributed data or too big to store on single machines
Two ways of accelerating workloads:
- adding more resources to a single machine (vertical scaling or scaling-up)
- adding more nodes to the system (horizontal scaling or scaling-out)
Scaling up:
- adding programmable GPUs is the most common method, as GPUs feature a high number of hardware threads (cores)
- An alternative to generic GPUs for acceleration is the use of Application-Specific Integrated Circuits (ASICs), which implement specialized functions through a highly optimized design, showing a significant competitive advantage over GPUs and CPUs to their high performance and power efficiency.
- Google applied this concept in their Tensor Processing Unit (TPU) for their Tensorflow framework. TPU is outperforming regular CPU/GPU setups for processing power and power efficiency, which is essential in large-scale applications due to the cost of energy and the limited availability in large-scale data centers. The performance per watt of a TPU can approach 200x that of a traditional system.
- Accessing the weights of neurons from DRAM is a costly operation and can dominate the energy profile of processing. Deep compression technique enables the weights into SRAM and accelerates the resulting sparse matrix-vector multiplications through efficient weight sharing.
- This special-purpose CPU is designed with a MIMD architecture that uses an array of processors, each accessing the same memory, to speed up the execution of floating-point operations. This is faster than giving every processor its memory because communicating between processors is expensive.
caling out (or combining it with scaling up) is preferred due to:
- lower equipment cost for both in terms of initial investment and maintenance.
- Resilience against failures - When a single processor fails within an HPC application, the system can continue operating by initiating a partial recovery.
- Increased I/O bandwidth - every node has a dedicated I/O subsystem, reducing the impact of I/O on the workload performance by parallelizing the reads and writes over multiple machines.
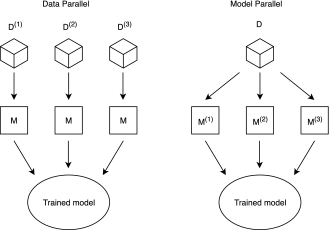
Image: arXiv:1912.09789
When it comes to distribution, there are two ways of partitioning all machines:
- In the Data-Parallel approach, the data is partitioned as often as worker nodes in the system, and all worker nodes apply the same algorithm to different data sets.
- In the Model-Parallel approach, exact copies of the entire data sets are processed by the worker nodes, which operate on different parts of the model.
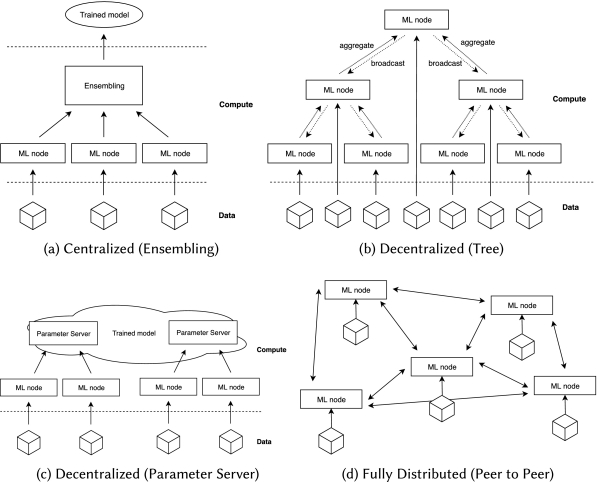
Image: arXiv:1912.09789
Decentralized systems allow for intermediate aggregation, either with a replicated model that is consistently updated when the aggregate is broadcast to all nodes such as in tree topologies or with a partitioned model sharded over multiple parameter servers:
- Tree-like topologies are easy to scale and manage, as each node only has to communicate with its parent and child nodes.
- Ring topologies require neighbor nodes to synchronize through messages, commonly used between multiple GPUs on the same machine.
- The Parameter Server paradigm (PS) uses a decentralized set of workers with a centralized set of masters maintaining the shared state. An advantage is that all model parameters (within a shard) are in global shared memory, making it easy to inspect the model. A disadvantage of the topology is that the Parameter Servers can form a bottleneck because they handle all communication.
- Peer to Peer topologies provide higher scalability than a centralized model and eliminate single points of failure in the system. Every node has its copy of the parameters, and the workers communicate directly with each other.
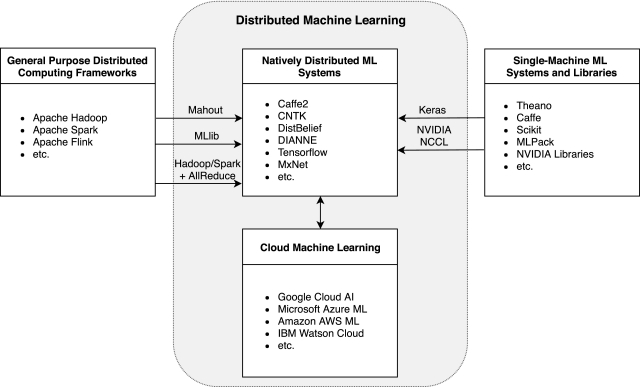
Image: arXiv:1912.09789
Natively Distributed Machine Learning Systems:
- DistBelief is one of the early practical implementations of large-scale distributed ML and was developed by Google. Every machine executes the training of a part of the computation graph’s nodes, which can span subsets of multiple layers of the neural network.
- Tensorflow is the evolution of DistBelief, which borrows the computation graph and parameter server concepts from it. TensorFlow represents both model algorithms and states as a dataflow graph, of which the execution can be distributed. The abstraction of the dataflow graph is mathematical operations on tensors (i.e., n-dimensional matrices).
Performance:
- A trade-off that is seen frequently is the reduction of wall-clock time at the expense of total aggregate processing time (i.e., decreased efficiency) by adding additional resources.
- Distributed use of GPUs, as in Tensorflow, has better properties but often still exhibits efficiency below 75%. These performance concerns are much less severe in the context of synchronous SGD-based frameworks, which often do achieve linear speedups in benchmarks.
Privacy:
- Federated learning systems can be deployed where multiple parties jointly learn an accurate deep neural network while keeping the data itself local and confidential.
Portability:
- Open Neural Network Exchange (ONNX) format defines a protocol buffer schema that defines an extensible computation graph model and definitions for standard operators and data types. Currently, ONNX is supported out of the box by frameworks such as Caffe, PyTorch, CNTK, and MXNet, and converters exist, e.g., for TensorFlow.
- Verbraeken et al. (2020). A Survey on Distributed Machine Learning. ACM 53, 2, Article 30 (July 2020), 33 pages. DOI: https://doi.org/10.1145/3377454